It's been 20+ years since I had reason to know the internals of BGP, but I still carry a slight nervousness whenever I think about it.
In many ways, it's beautiful in that it allows Autonomous Systems to come together and independently make the Internet.
However, I always felt it was brittle in that it relied every AS to have edge routers aware of the entire AS routing map, and so when those routers went down hard, when they came back up they were blank and needed to learn the Internet again. I noted back then that on some routers a single spoofed UDP packet to a router getting a table from its peers could cause it to stop doing that and start again. In a time when those updates could take hours... well... that kept me awake at night sometimes.
Propagation of routes was global and error prone. Even today, you can see on the spy glass websites rogue AS routers advertising crazy routes either by accident or on purpose as a hostile act (to try and get traffic for a target network through itself).
There are tens of thousands of engineers globally nursing and managing this stuff to keep the whole thing going.
Like I said, it's been a while since I last looked closely, and I imagine multiple improvements have been made in this space since that time, but if there was ever a protocol that needs a long, cold hard look for a replacement, it's quite possibly BGP.
It's also the one - and only - non-crypto situation where if somebody asked me if a blockchain could be really very useful, I'd say "probably, yeah".
These are abstraction barriers that isolate locations, layers and protocols from each other. I don't understand this as translation but rather as a separation of concerns.
Thanks for not pushing back too hard on my (elderly?), ignorance, and giving me a chance to catch up with the current state of the art. This looks very interesting, and I am looking forward to spending time diving in for no more than a sense of curiosity. Thank you.
Problem is the blockchain stuff usually ends up being computationally expensive for what it's trying to do.
I could maybe see a use case for DNS but then either each computer has to have the full blockchain locally or rely on providers to do that for them in which case we're basically at the same model we have now (with root servers and DNS servers).
Obviously you don't want to publish private IPs, etc. to other computers... so inside a local network you're not buying yourself much.
For routing tables I could see more of a use case for blockchain technology since you can actually verify the routing tables and prevent BGP spoofing, etc.
This is a great write-up, but one thing I don't understand is why the effect of withdrawing the BGP prefixes was instantaneous (if I understand that correctly), but it's taking hours (so far) to re-announce the prefixes. Why would it take so long to flip the switch back the other way?
At a guess: reconnecting traffic at the billions-of-people scale has the potential for finding all sorts of weird behaviours. For all we know, it has been connected and disconnected 10x already during the outage, with each reconnect overwhelming some new, deeper level of the system each time.
Reconnect and the GLBs fall apart under load as the entire world’s cadre of recursive resolvers hit you.
Fix that. Reconnect again. This time your LBs have marked half the servers as offline because their heartbeats have been failing.
Fix that. Reconnect again. Now all the memcache data is hours old and so the site business logic fetches straight from databases, knocking them over.
I find this kind of uninformed conjecture amusing on a thread full of people complaining about cloudflare doing the same (they didn't). There's no evidence of this kind of flapping behavior in any of the telemetry I've seen posted by network engineer friends, and the blog post explicitly calls out when they saw the BGP updates that brought the site back online.
For me, the hardest part to believe is there was literally no one on-site at their datacenters. Really? No one? At this scale, literally, there has to be a security guard there who can kick the door open.
Reminds me of when I was working at a startup we DOSed ourselves. We had devices that monitored power minute by minute. A load balancer was mis configured and we went down for a some hours. We came back up and the devices all saw that and flooded us with all the data they’d been storing since we were down.. down again… bring it up and down again…. we needed a better fix. I was up till 2 am with the other developer coding a fix.. the next morning we talked to the CEO (CTO was on vacation)who told us upgrading the was database was going to be too expensive… good times. We did get a firmware fix ( to be honest we were running out of cash..)
I can’t imagine trying to restart something as big as facebook…
Unpopular opinion but I think a talent exodus and turnover are likely at fault here as well. The people who stood up this juggernaut are no longer here, and Facebooks ability to consistently attract talent that is competent enough to maintain such a formidable beast is hampered by repetitive revelations that it operates at the net-loss of humanity as a whole.
Facebooks no longer an innovator, just a mining operation with a dwindling population of hateful elderly and bots.
Isn’t Facebook huge in some Asian countries? Supposedly 3.5 billion people use one or more of its services. WhatsApp, Instagram and Oculus certainly aren’t just used by the elderly.
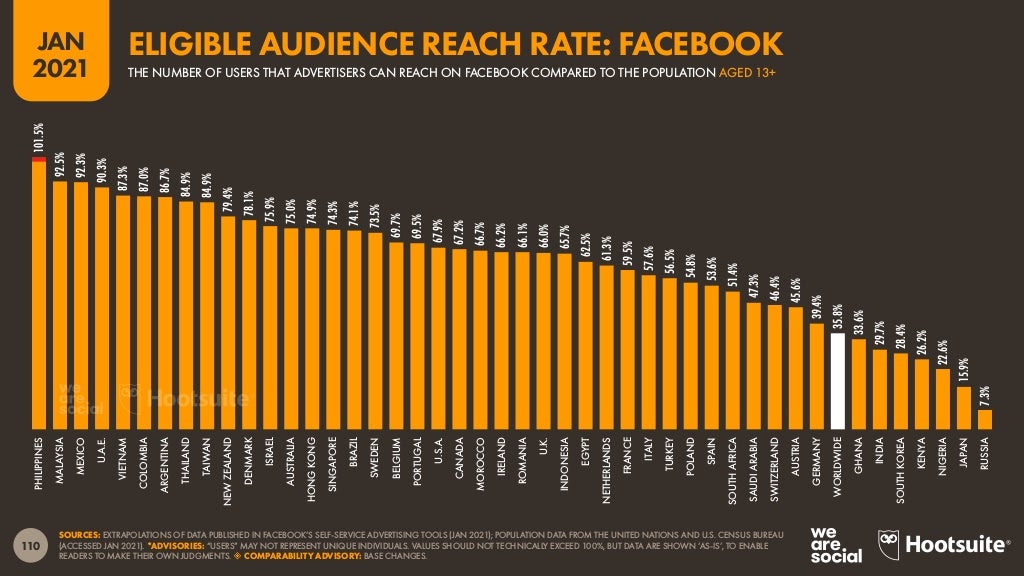
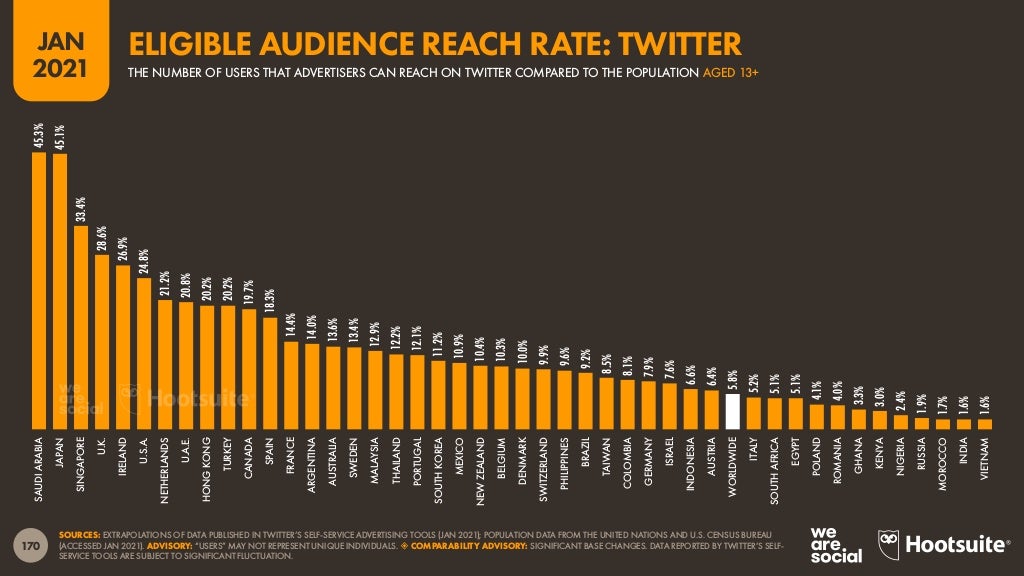
Depends on which specific country you mean by Asia, as nations are kind of culturally segregated by sea and by heritage in Asia - I mean, Instagram is but Facebook itself is smol in Japan[1] and Twitter is bigger unlike anywhere[2] (taken from page 110 and page 170 of "The Digital 2021 Global Overview Report" from we are social/Hootsuite[3]).
Anecdotally around 90% of the people I know in the UK (40s age group ) have Facebook and use it for something (even if it's just for checking restaurants/gigs etc), almost everyone uses Messenger or Whatsapp. Also for those saying they use Facetime, stats suggest that half phones in the UK are Android. FB is relevant, even if you want to be, maybe in the same ways Windows/Microsoft is relevant for a whole load of people.
Taking a bet that complex systems will fail is usually free money :).
Having been a part of Google the only thing more awe inspiring than the sheer complexity of production is the fact that it all worked so well.
This is not a dig at current Googlers but entropy is cruel and uncaring. Perhaps parts of the stack which have been kept fit & fresh in people's minds due to constant rewrites will last longer but there are tons of places in the depot that are unowned despite serving production query traffic and the number of engineers that have any context to support it grows smaller over time.
Google (at least the good parts) has a pretty good culture of documentation, which helps a bit. While it drove me batty to need to spend a month writing up 10 page specs and getting sign off from directors for a minor feature that nobody would see and would take 3 days to code up, it was nice to be able to trace through the historical evolution of abandoned features when trying to figure out how they worked.
I haven't been following closely, but I think once they moved the prefixes they could no longer access the routers. Coupled with barebones staff at the data center due to the pandemic, and all internal communication being disrupted. Though I really expected it to be up within an hour or two.
We have had out-of-band management ports & networks design for decades! I know the feeling of driving 8 hours because I lost connection to the device I was configuring. https://en.wikipedia.org/wiki/Out-of-band_management
This. And if you're really worried about it you can go crazy with security with individually issued hardware security tokens and one time use access tokens.
It's pretty inexcusable that FB wasn't able to use OOB management.
Yeah, I think that is true. If you look at the Update near the end of the Cloudflare article there is a huge spike in the BGP activity (I assume re-announcing all of the routes). So that part of it was relatively instantaneous after they got all of their ducks in a row actually getting to the routers and locating the BGP from some earlier version before it went offline this morning that they could use.
Presumably they're working remotely, but the incident required physical access, so only the reduced number of people present were (immediately (or at all, I don't know their policies)) available to deal with it.
Restoring is just as simple as flipping the switch again, but access to that switch is another matter when your internal network is also down and you cannot even get access to your office or datacenters.
What I don't get is why there is no dead-man switch mechanism in place to roll back the configuration automatically unless someone confirms it positively. Kind of how screen resolution rolls back if you don't ack it. I used to always run a "(sleep 600; iptables -F) &" when messing with remote personal stuff just in case I lock myself out.
I suppose with something like BGP it would be very difficult to get such a fallback working given how distributed the system is, and even more difficult to keep it exercised and tested.
This is a key feature of Junos on Juniper devices. It's called 'commit confirmed' and it will apply the config and then auto-rollback if you don't confirm it within a certain amount of time.
I’m pretty new to BGP, but I’d imagine that cutting off access to an AS is fast because all it takes is for the neighbouring routers update their routes. At which point any traffic that makes it that far is simply dropped.
Whereas to make an announcement, the entire internet (or at least all routers between the AS and the user) need to pickup the new announcement.
I think it's not so simple because authoritative DNS systems are involved.
So it's not just a BGP error. It's a BGP error which disconnected authoritative DNS for all facebook. I'm not quite sure why that makes it so slow to fix. is it just because internal difficulties due to having no DNS at all?
I'd assume it is a cache invalidation problem at that point: from my lay understanding BGP probably needs to busts caches on a withdrawal to keep traffic from going to black holes and prevent DDoS attempts, but probably has to wait for TTL timeouts to cache new routes (and those TTLs are going to vary by whatever cache systems the other ASes are running not the timing of Facebook's AS sending the new [old] routes.).
BGP doesn't really cache routes, though you can configure routers to hold a route for some time if a peer times out, but this is only used in special cases and usually not something you would want your router to do with routes to other networks. If a router gets a withdrawal for a route it will remove the route from the table without waiting. This is a feature and important part of how BGP acts in case of problems and how it can self heal quickly, there's no point in caching a route when that path is not working anymore and usually there's a backup path.
Given my experience with DNS issues, I am guessing that they are running into dependencies along the way that assume/require DNS be available to function.
With routing it's even worse than that. If they had no out-of-band method to connect to these routers and they botched the routing config then they had no way to route any traffic to them at all. At least with DNS you can still connect to the IPs.
I would find it a bit surprising if Facebook didn't have OOB access to their data centers, however.
I'm sure they got stuck in a security loop. To get access OOB passwords or IP address, they needed to get into a password vault that is under facebook AN.
Next time FB save you passwords in OneDrive and Google Drive as a backup LOL. facebook-oob-password@gmail.com
Yeah as part of my job I often have to work with our DNS team to provision say a subdomain or get some domain verified. They’ve got like…three people…trying to service thousands of teams across the enterprise. I do not envy their job at all.
It's an IP address management (IPAM) solution that also just happens to be a fantastic, federated (if you want) DNS management system too. Indeed a previous org I worked at bought it strictly to tame the DNS beast - local sys admins could control DNS for their subnets but not affect anything else. If we wanted, we could have had approval processes on top of the change requests - the system supported that too.
I think the security teams finally woke up to the IP address management functionality and were slowly starting to integrate that into the rest of the infrastructure - but I was leaving around then. It was a fantastic system. One of the best hierarchical role-based access control systems in an application I have ever seen; the granularity was amazing yet it was easy to understand/administer. Not an easy trick!
I'm not sure if that is true (and I hope it is not cause that would be fatal) but I read somewhere that with facebook being down also means all internal infrastructure of facebook isn't available at the moment (chats, communication) including remote control tools for the BGP Routers. Therefor they require people to get physical access to the router while many people are working from home cause of the pandemic.
It just a guess, but from experience with BGP and associated redundancy systems that most likely was in place, if everything doesn't return immediately then you have a big fight on your hand to not only stop the non-functional redundancy but also reestablish the peer connections with associted hearthbeat/processes for establishing and maintaining the peer connection. My understanding from what people write about configuring BGP and the system around it seems to imply that the best practice in this circumstance is to kill everything, fix the original error and then turn on things slowly again. Then fix the broken redundancy configuration. Then test the redundancy system regularly in the future.
I feel like it just confuses the issue with a bunch of unnecessary babble about DNS, theres better ways to read about how BGP works without confusing a bunch of different things. The only part of the article that was relevant was 'Routes were withdrawn' - the rest being a consequence of that.
You have to be careful turning something as large as Facebook back on. If you turn on announcements one place first, the entire internet will try to reach you through a single transit and overwhelm it.
The kind of tail you’re talking about is baked into DNS at least.
I don’t know enough about BGP to make an informed decision; but at the point the outage is noticed it’s entirely possible that the system has been unavailable for quite some time already.
fast off board slow onboard is a pattern you find all over. it has roots in fraud but there’s many reasons. getting more access is a privilege escalation and requires some trust to achieve
If an authoritative DNS entry was removed, it can take up to 72 hours for that change to be propagated around the world, though usually just a few hours for some other authoritative DNS systems to get you mostly back:
Resolvers typically cache successful "does not exist" responses for no more than 1-3 hours. (And authoritative servers often have a lower negative TTL.)
(There's a corner case related to DNSSEC that can make it go higher, but that's being worked on, and isn't relevant here.)
In this situation, the nameservers were just down. I haven't done exhaustive research, but the resolvers I'm aware of cache that kind of thing for no more than 15 minutes.
How can you explain yesterday's outage (Facebook, Instagram, WhatsApp) to your parents?
You are feeling hungry and went to food court. The food court (open area) has a lot of options. You sit down in front of Domino's (Facebook), since you want to eat garlic bread. Now, you can't order from the counter directly. The waiter will come to your seat and ask for the order. You ordered garlic bread from the waiter, but the guy at Domino's counter went missing. Your order was not reaching to the chef in kitchen as Domino's counter guy was not present.
This explains why Domino's (Facebook) ecosystem was down, but what about other vendors? They had nothing to do with Facebook.
To understand this, we need to go back to our food court again. Now, there are a lot of hungry people sitting outside Domino. Since they were not getting answer from one waiter as why their food is not on their table, they started disturbing all the waiters. Due to this, majority of the waiters were trying to figure out where the Domino's counter guy went and other food joints (read websites) were not able to fulfil their own orders.
So although only Domino's was down, it appeared as if whole Food Court (Internet) was facing issues.
Counter Guy at Domino's - Facebook Nameservers
Waiters - DNS Servers (Cloudflare, Google, Akamai)
I'd just say that you had an address for Facebook in your address book. The page somehow vanished and you don't know their address any more. So you start phoning other people and knocking on their door to try and find what their address is. Everyone else is doing this and no one knows what their address is. So you've got millions of people phoning each other and knocking on doors.
Facebook being down was already an issue, but everyone phoning and knocking on doors was causing disruption to everyone else.
There is no need to make it any more complex than "facebook, the company, messed up, now their properties are broken". An overly elaborated analogy just makes you sound condescending.
Internet is just a bunch of computers interconnected via tons of cables (hence the name; "inter-networked computers").
To be reachable, every equipment and computer constantly need to tell the others about their existence (to publicly announce on which network cable they can be reached at).
Facebook engineers wanted to optimise that system but accidentally broke it during the update.
As a consequence, after a few minutes, other computers didn't know on which cables they can reach Facebook.
Facebook had to call the technicians sitting in the datacenter to cancel the last change that was done (because the Facebook engineers couldn't themselves connect from the office) and everything was fine again.
That would have been accurate for a DNS outage ; but with my layman understanding of BGP, I would say the analogy would be something between "...but their phone line is broken" and "...but they disappeared from the phone book because they don't have a phone line any more" .
Actually, it probably is, especially if you dial the analogy back a couple decades before the "We're sorry that number has been disconnected" automated responses: Facebook's phone line went down and when you call the Operator even if you have the phone number, they can't connect you, but this is weird and you aren't the only one trying to call Facebook so now they are calling in other Operators to diagnose the problem because surely someone has heard from Facebook recently.
That analogy includes the snowball impact on the other websites and services as the Switchboard Operators get more over-utilized into puzzling out Facebook's problem than servicing calls for still working phone numbers.
Even google isn't quite sure about the summer time.
Not sure if that is just a Google German thing...
A few weeks ago I tried to find out what the current time in CET is.
Asking google for "CET" gave me: "23:27 CET".
Asking google for "CET time" (I know that "time" is twice in this case) gave me "00:27 CET".
The last one is wrong and should be CEST or even more correct would be just the same result for CET as I asked for
I am always forgetting the polarity. Seeing the cut-overs listed helps me:
$ zdump -v Europe/Berlin | grep 2021
Europe/Berlin Sun Mar 28 00:59:59 2021 UT = Sun Mar 28 01:59:59 2021 CET isdst=0 gmtoff=3600
Europe/Berlin Sun Mar 28 01:00:00 2021 UT = Sun Mar 28 03:00:00 2021 CEST isdst=1 gmtoff=7200
Europe/Berlin Sun Oct 31 00:59:59 2021 UT = Sun Oct 31 02:59:59 2021 CEST isdst=1 gmtoff=7200
Europe/Berlin Sun Oct 31 01:00:00 2021 UT = Sun Oct 31 02:00:00 2021 CET isdst=0 gmtoff=3600
In this case, Google is providing a wrong answer to not confuse people. People don't understand that a time zone can exist but not be observed at the same time
I make a point to give local times in just "PT". Not least among my reasons is that I can't ever remember which half of the year is Daylight time and which is Standard.
I personally find timezones more annoying. At least with encoding once you figure things out it will work indefinitely. Timezones can simply change from under you with or without notice.
No joke. Today I ended up writing a whole essay explaining the issue I was having and almost sending it off to the core developers because I thought I had discovered an issue with the actual language. The bug was because I had forgot to convert too&from utf-8 in these two procedures:
Actually, the article seems to confuse the times quite a lot. It's talking about ~16:50 UTC at points, but the outage started at 15:40, which they not only mention in the article but you can also see on the graphs.
Question about the WARP map - I assume the grey countries are places where Cloudflare doesn't have any presence, but what about Egypt/Oman? Why are they green? And why is Australia orange and not red?
This provides a good set of details (mostly educational) what happened up to but not including the how and why the BGP routes were withdrawn (who sent the UPDATE packets to the neighboring ASes?).
The most "natural" occurrence that I can think of is best-path change. If a "better" route between AS is added, the now-second-best routes are withdrawn.
Correct me if I am wrong, but there is no way of determining the source of the withdraw message (UPDATE)...
> "Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication. "
and
> "... its root cause was a faulty configuration change on our end."
All very amusing. But most amusing was that facebook employees' badges wouldn't work. Hilarious. Can't get in the office if facebook.com is not reachable. (or whatever the unreachable service was)
Far fetched, obviously, but.... Jurassic Park, Dennis Nedry-type situation? Shut down the master systems to hide the theft (or in this case, destruction) of vital info.
No key-card access means even non-need-to-know internal employees wouldn't see the deed, and plausible deniability is spawned for everyone else.
The second explanation seems plausible to me. The first one is a bit farfetched since they could've just waited two weeks in order to make it look less suspicious given that the leak would not be front of mind for everyone by then.
I read on Facebook that Nicki Minaj's Cousin's Friend was using an Oculus during the Facebook outage, and he got trapped in CyberSpace, and when his balls became swollen in CyberSpace, they also became swollen in real life!
Oculus customers were only able to play offline games during this time. Which I find concerning. I don't mind that FB employee badges didn't work because what would they do at their desks anyway and all exit doors have bypasses anyway so they can, and were, open, just rank and file employees couldn't access some spaces. Some of those spaces are secure and "fail closed" by design. Yes, its inconvenient but unlocking all the doors to potential terrorists or workplace shooters if the internet connection gets snipped isn't what you want in an office.
What's scary is that my gaming machine can't be used because of some weird obsession with centralizing oculus through facebook. As a customer that's inexcusable but now imagine a developer who hosts her own servers for her game and her customers can't get to it. Facebook is only providing middle-man authentication, its not even hosting these games. If they were hosted by FB it would be fine, but they aren't and what we're suffering under is FB being the gatekeeper to the rest of the internet. That is a scary prospect.
I also question why we all think its acceptable to have these incredible BGP outages every 3-6 months. We built our digital world on the equivalent of ever changing spinning plates and manage it in the most cost-efficient way possible. Maybe the alternative would been worse, but its crazy to me as to what we consider normal and acceptable in capitalist culture.
I'm already seeing /r/oculus say its no different than Valve's scheduled maintenance windows, which is obviously false. Its incredible what rationalizations we'll accept instead of questioning the status quo of capitalist culture and our giant corporations that rule so much of our lives.
> I also question why we all think its acceptable to have these incredible BGP outages every 3-6 months.
This isn’t BGP’s fault, someone or something presumably made a network configuration change that took down their route advertisements to the world. There’s currently ~72K autonomous systems advertising ~900K IPv4 prefixes today on the Internet. There’s bound to be some sort of screw up once in a while.
Curious about this as well could not find anything on initial searches but I honestly hope so. The one reason I have not grabbed the oculus is because the Facebook requirement.
When I hear Facebook leadership talking about the VR vision, I’m reminded of IBM in the early 2000s encouraging employees to claim their second life avatars and setup cyber customer briefing centers.
Exactly ... like I am going to strap on a headset and work with my co-workers memojis for 8 hours or even less. Laughable and VR has been around since the 90s with the same form factor .. it hasn't evolved as it will always be strap this bulky thing to your head & isolate yourself from the world. Maybe it will catch on for videogames but to co-work in a virtually reality world HA.
AR Glasses at least their form factor has changed since Google Glass and will continue to evolve some. Google Glasses to how Facebook Stories sunglasses look which look like sunglasses billions are use to wearing and use daily. Billions will never strap on a headset for hours to co-work. Billions will adopt AR Glasses as it takes a familiar form factor/daily life product and enhances it like the iPHone enhance our daily lives.
Eh, I could see myself doing development in that type of environment if the tools were get better. I've worked remote for the past 6 years, so it wouldn't quite be the same as in an office environment though.
You would think those in charge of security would know better with their mid-six figure salaries. But then again these days they stopped hiring based on merit but rather certain other “metrics” no wonder they were so incompetent...
The person you're replying to is insinuating that Facebook hires half-a-million dollar engineers based on diversity quotas instead of technical chops. No sense asking them to elaborate since they're obviously completely outside the company and have no worthwhile insight into their hiring practices.
"Diversity quota" is one interpretation, mine was that they meant FB hires were determined according to who you know and who you blow. (probably less of the latter post-#metoo)
Is there a petition to make this permanent? Asking for a friend
The article itself was a good exploration of the impact of BGP and what happens when network advertisements stop and the associated network disappears in a puff of global forgetfulness.
Might be time to poke around BGP as well. A lab setup might be a good toy.
Lets assume somebody messed up their BGP config. Does anybody know if they use Juniper? Why they would not do the changes via "the commit confirmed" option?
The idea is you do something, you messed up and are locked out, the system will revert to previous config after a few minutes by itself. The story of people physically accessing
systems only makes sense, if this was a hack...
===============
Commit Confirmed
"Suppose that despite all your efforts to insure your new configuration is correct before you commit it, something is overlooked and when you commit, you are locked out of the router."
"Rather than just a simple commit, you can make the candidate configuration active with a commit confirmed command. With this command, the router waits 10 minutes for a second commit. If it does not receive that confirming command within those 10 minutes, the router automatically does a rollback and commit so that the previous configuration becomes active again."
This and other stories seem to assume that a BGP issue is the root cause. That may be, but there are other possibilities.
Some other internal issues could have broken many systems, including BGP.
They could have had some sort of internal systems failure, and intentionally withdrew BGB to cut off the flood of connection attempts (making recovery easier).
Is anyone else kinda put off by how Cloudflare keeps interjecting themselves into this situation? First with the Twitter posts and now this blogpost. They're a passive observer, not involved in this event, and yet they keep putting themselves in the middle of it.
Cloudflare staff are not Facebook staff, they do not know how things actually went down to trigger the events that transpired. They are essentially doing glorified bikeshedding, and providing an explainer of how BGP works that can be gleaned by reading virtually any introductory text on it, and using it as a marketing opportunity.
> They are essentially doing glorified bikeshedding, and providing an explainer of how BGP works that can be gleaned by reading virtually any introductory text on it, and using it as a marketing opportunity.
I mean, I'm not really sure what the purpose of a corporate blog is except that? You make posts about whatever will garner attention in order to get some views, maybe spread some information, and - of course - turn it into a marketing opportunity. That's the job, no?
> Is anyone else kinda put off by how Cloudflare keeps interjecting themselves into this situation?
Personally? No. Although amusingly, a non-technical friend of mine took the twitter posts they made as a sign that Cloudflare had caused the outage somehow, so it's certainly possible there's a risk there.
And from one of your other comments:
> Next time Cloudflare's CDN eats itself and starts vomiting up private customer data, Facebook can do a blogpost titled 'Understanding how Cloudflare exposed the private information of untold numbers of its customers'.
Yes, they should totally do that (at least if they have anything informative to contribute, as I think Cloudflare does here). Why would this be a bad thing, or a reason not to talk about Facebook's issues? And I mean, at one point today something like 6+ of the top 10 links on HN were about Facebook, so I mean, everyone else is talking about them. Why not Cloudflare? And if and when Cloudflare has their next big issue, everyone will be talking about them either way.
The CEO recently pointed out on Twitter that the primary purpose of the company blog was hiring, and that the company would write with that in mind. The post taught me something I didn’t already know, and left me more impressed than I was before with Cloudflare. Mission accomplished.
I mean... they're in the business of keeping websites online. It's natural that they document these events both for their own research and to market their product.
It's merely an informative blog post on a topic many people are interested in. I see nothing wrong with Cloudflare just explaining what happened, even though they had nothing to do with it.
It is little stuff like this that makes it come off a bit self-aggrandizing:
> We keep track of all the BGP updates and announcements we see in our global network. At our scale, the data we collect gives us a view of how the Internet is connected and where the traffic is meant to flow from and to everywhere on the planet.
> Fortunately, 1.1.1.1 was built to be Free, Private, Fast (as the independent DNS monitor DNSPerf can attest), and scalable, and we were able to keep servicing our users with minimal impact.
It isn’t a big deal, and the posts are still interesting. It just makes me roll my eyes a bit.
> I see nothing wrong with Cloudflare just explaining what happened, even though they had nothing to do with it.
You kinda inadvertently highlighted the issue: because they had nothing to do with it, they do not know what actually happened. They can pontificate about likely causes, just like others in the industry can, but they have no idea what actually caused the issue.
At no point in the blog post did they offer any conjecture about what was happening at Facebook. All of their information was general descriptions of DNS and BGP, or descriptions of how the Facebook outage was experienced on their end from running a DNS resolver. That in and of itself makes for an interesting and informative perspective.
I assume you did not read the blog post? It’s just a technical post describing the outage from Cloudflare’s perspective and mostly focuses on the increased traffic to 1.1.1.1 and the latency it caused
You can pontificate about likely contents of Cloudfare’s blog post, just like others who did not read it, but clearly you have no idea what it actually contains
If you read the blog post, you'll see that it's speculation-free facts about what happened. BGP announcements happened at time t, DNS started failing at t+n, DNS requests spiked, BGP updates happened at t', DNS returned to normal at t'+n.
They've done this in previous outages and people didn't like it then, either.
Generally big companies don't talk smack about other big companies having internet-wide issues, unless those issues are directly caused by the other company.
For instance, when Google talked about Cloudbleed, which was when Cloudflare vomited millions of secrets all over Google's caching heirarchy and Google had to manually clean it up.
I think perhaps the Cloudflare people have gotten confused and think that means it's okay to talk about other people's stuff. Instead of interpreting it as it really is, which is that Cloudflare is the last company that should be criticizing everyone else, lest someone bring up their previous missteps.
Given that warp is a pretty major player in the VPN space and lots of their customers are likely to blame them for not being able to get to Facebook, I think having a detailed "wasn't us" on their blog that their sales engineers can point to is reasonable.
I kinda see your perspective; but I also mostly view them similarly to e.g. BackBlaze blogs - sure it can be viewed as taking smack about Samsung and Seagate drives failing, but I seem them as "things fail; what can we learn from it / here's our observations". And yes a little bit of self-advertising, but again, most tech blogs are, one way or another.
It just comes off as crass. Next time Cloudflare's CDN eats itself and starts vomiting up private customer data, Facebook can do a blogpost titled 'Understanding how Cloudflare exposed the private information of untold numbers of its customers'.
As someone who is always interested in learning new things, their blog post is informative and helpful. Not everything is about optics, their intentions are of no interest to me, because I got some value out of the content.
how are they 'interjecting' themselves? They run a massively popular dns service as well as many other sites, and they are simply reporting on what happened and why people who use their dns etc might have had outages. In addition to being a very detailed and well written article on the whole incident. Not really sure what you are driving at.
At the fact that they are presenting themselves as authorities on the incident, when they have no internal knowledge of what triggered the events, because they are not Facebook engineers. They provide an explanation of BGP that you can glean by reading virtually any other introductory explainer, and turn it into a chance to promote their own service.
>At the fact that they are presenting themselves as authorities on the incident, when they have no internal knowledge of what triggered the events, because they are not Facebook engineers. They provide an explanation of BGP that you can glean by reading virtually any other introductory explainer, and turn it into a chance to promote their own service.
This is not an honest representation of the article.
They talk about what their services observed related to bgp traffic from facebook. They are an authority on that.
They talk about their dns traffic changes from facebook's outage. They are an authority on that.
They talk about suspected causes, based on the observable data, and guess what, given they are who they are, this is something they are a subject matter expert on.
"we saw a spike in bgp traffic from facebook followed by a bunch of route withdrawals. we think this could be a bgp configuration issue [given we took large chunks of the internet down 2 years via the same fuckup]"
Is something in the subject matter wheelhouse of cloudflare, yes.
Ironically, I read this and thought "I like this and these people are doing the sort of things I like doing, maybe I should think about working with them if and when I need another job."
Sample size of 1, but I imagine that's more or less the reaction they're hoping for.
The whole blog post seemed like a click and bait to me.
Nothing is "explained" other than what we knew already, that some unlucky SOB shot themselves in the head with a BGP shotgun.
I understand, they have no way of knowing what happened inside Facebook. But they could give some detail about exactly what the BGP updates were, the structure of the IP space served etc.
It’s massively viral news about the exact stuff they specialise in. I’m not too surprised that they’d be putting out content. After all, Facebook is hardly in a position to do so ;)
They seem to be treating it as a marketing opportunity, as well as explaining these topics for journalists. If their post didn't add to the public conversation, it wouldn't have been so viral.
Krebs did not promote a DNS service he works for a total of nine times in his blogpost, so I did not feel like I was reading an infomercial for how great Cloudflare's continued MITMing of the internet is.
No issue with his openly admitted speculating though? That seemed to be in-part your issue with Cloudflare in many comments, even though they were talking about something specific to its impact on their service.
it's kinda their whole objective- to keep sites up and running. so of course they'll do commentaries- it's for marketing and helps stimulate discussions in their industry.
No surprises here. They do it all the time for websites they cdn. Cloudflare might as well be a marketing company for how much they puff about themselves.
They state that [1] this only happens if you are using more than 3 Page Rules that the free plan allows, which is fair. The alternative would be to randomly delete some of your page rules, which is worse:
> If you do not want to be charged for the additional page rules, you should ensure you only have 3 active rules before you downgrade from Pro to Free.
I don't trust any analysis from CloudFlare. These are the same people preventing people with vpns or tor browsers from reaching sites while screaming and yelling OMG DDoS!! then blaming the customer of CloudFlare for not knowing how to configure it.
Maybe a timed rollback with the previous state stored on the device that needs to be rolled back, althogh if you're doing this at facebook scale I'm sure that's a little more difficult than it sounds, perhaps.
How I explained this to friends and family: Imagine that the only way to get to Los Angeles is to use a GPS enabled device. All of the maps know how to get there from anywhere. But imagine that every GPS took Los Angeles off the map. Los Angeles is still there, but nobody knows how to get there. That's what happened to Facebook. We don't yet know why, however.
Why? Do you think there's billions of widely-used recursive resolvers in the world? Each resolver only needs to contact the Facebook DNS servers once per hostname, the end-user requests are all served from cache.
From article:
[This chart shows] the availability of the DNS name 'facebook.com' on Cloudflare's DNS resolver 1.1.1.1. It stopped being available at around 15:50 UTC and returned at 21:20 UTC.
How would they push an update if they couldn’t reach their own network?
My understanding is that if a bad BGP route was pushed and your whole network (typically accessed via VPN while the engineers WFH) is probably unreachable from any of you’re employees’ homes, it’s hard to get the right people on site to make a fix, or talk the remote hands folks at the date center through it over the phone. Troubleshooting is hard, troubleshooting while you have no access to your own network has got to be just that much harder.
This happens the day after the whistleblower's 60 Minutes interview? Maybe another rogue (whistleblower is surprised Facebook is a for profit business focused on profit .. not saying good or bad given how big facebook is but really how do you police the world and what side do you take in all the madness/negative parts that make up humanity thus facebook) Facebook employee took it offline ... any chance of that?
Those short TTLs that FB likely has on its DNS records probably bit it in the ass today. If it had longer TTLs, caching would have helped it. Curious though that recursive resolvers won't serve an expired cached record when they can't reach the authoritative server. (I know that unbound can be configured to do so, but not sure about others.)
I don't think so. The root cause (as I understand) was that FB stopped advertising it's IP address space to the world. Even if you had the IP addresses of the FB servers, you would not find any route to access them.
The fact that DNS was also not resolving was a symptom of the DNS servers also being unavailable since they were part of the same IP address space that was unadvertised.
Stuff like this happens... but the real question is why FB had to send employees to physically go to datacenters to fix this. Sounds like their OOB management had a dependency on FB being online which seems like a bad design. If you're that paranoid about security issue revokable one time pads to a select set of employees.
Let's say that when Facebook cannot announce their DNS prefixes, the DNS resolvers from other ASes cannot reach their DNS servers. But why? Does Facebook change the IP addresses of their DNS servers and other web endpoints constantly? Shoudn't Facebook IP addresses be cached by DNS resolvers?
I think that it is possible to restore the previous state but the question is, if it makes sense. When do you decide that it was a failure? Facebook explicitly (even so automatically) told all others that they shouldn't use that routes anymore.
When it comes to Facebooks side I guess they do have backups of their BGP config. Applying them (probably remotely) however seems to be harder then expected when the whole infrastructure is down.
Once upon a time this would have been the norm. If we were performing any DNS related maintenance we'd drop the TTL to 5 mins a day or so before the maintenance window was due to start. Once happy we'd not broken anything then we'd bump back to 21600 or whatever. But I guess the move fast/break all the things crowd no longer have any patience for this kind of thing.
Do you really think that Facebook is going to write one right now?
It's good that we have some coverage from companies that have some stake in the game because they are also affected by the outage, even if only partially.
Facebook has to make some public statement; the shareholders will demand it.
I expect the detail level to be roughly "an automated system pushed a broken configuration"; that is to say, there probably won't be any interesting information at all for the Hacker News crowd.
I doubt that this was caused by "hackers" or "hostile governments" or "dissident employees upset about Facebook privacy issues", and also doubt that Facebook would admit such if it were true unless they were legally required to do so.
History has shown us they can give us zero response, or an incorrect response, and we (via our representatives) will accept it and continue living life as before.
The fact is, it's altogether likely that they could be legally require NOT to make such a statement outlining the cause if it was a hostile actor. I've felt a distinct change recently. The US government is not messing around about cyber security anymore.
The guys with the blue windbreakers show up, I'd pretty much say "yes, sir." Of course, I don't have FB's power, but I don't think it matters.
Also short comments without discussion and evidence do poorly.
I believe it should be halted for public safety which is well within the rights and capacity of our government. I believe a fair trial should happen before anyone receives punishment, but I don't believe we could find an impartial jury as Facebook is ubiquitous.
{kind=link}
{kind=link}
In many ways, it's beautiful in that it allows Autonomous Systems to come together and independently make the Internet.
However, I always felt it was brittle in that it relied every AS to have edge routers aware of the entire AS routing map, and so when those routers went down hard, when they came back up they were blank and needed to learn the Internet again. I noted back then that on some routers a single spoofed UDP packet to a router getting a table from its peers could cause it to stop doing that and start again. In a time when those updates could take hours... well... that kept me awake at night sometimes.
Propagation of routes was global and error prone. Even today, you can see on the spy glass websites rogue AS routers advertising crazy routes either by accident or on purpose as a hostile act (to try and get traffic for a target network through itself).
There are tens of thousands of engineers globally nursing and managing this stuff to keep the whole thing going.
Like I said, it's been a while since I last looked closely, and I imagine multiple improvements have been made in this space since that time, but if there was ever a protocol that needs a long, cold hard look for a replacement, it's quite possibly BGP.
It's also the one - and only - non-crypto situation where if somebody asked me if a blockchain could be really very useful, I'd say "probably, yeah".